
Pytorch nn-Module
2020-12-18
[toc]
nn.Module
继承nn.Module类
在nn(neural network)模块中,有一个nn.Module类,这是一个快速构建神经网络的基类。你可以通过继承这个类,并重写forward(input)方法,来创建一个自定义各个网络层的神经网络类。例如下面这个Net 类定义了一个LeNet-5网络。
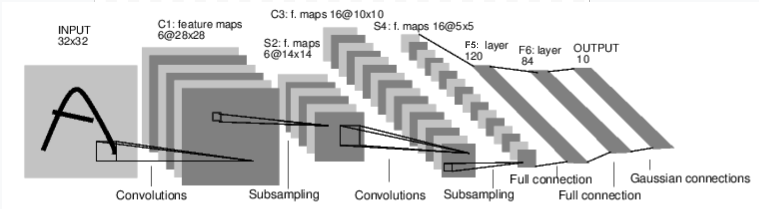
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
上面用到的nn.Conv2d计算的对象是4维的,维度依次为(nSamples, nChannels, Height, Width),也就是input需要按照这个顺序排列。如果传入的是单个Sample,可以通过input.unsqueeze(0)增加一个sample维度。参考unsqueeze
nn.Module继承类的调用
nn.Module类通过方法__call__()来使类的以函数调用方式返回forward的计算结果,为了说明,下面是nn.Module有关的最简定义:
class Module(object):
def __call__(self, *input, **kargs):
return self.forward(*input, **kargs)
因此,当执行out = net(input)时,实际上返回的是forward方法的返回值,是一个带grad_fn属性的tensor。
parameters()方法
parameters()方法可以返回遍历这个网络的所有参数的迭代器,一般使用for来遍历。例如:
for param in net.parameters():
print(param.size())
# >> torch.Size([6, 1, 3, 3])
# >> torch.Size([6, 16, 3, 3])
# >> ...
zero_grad()方法
net的反向传播过程的梯度累加的,所以每次backward()都会将新的梯度累加到grad中,因此,除非必要,我们应该在每次反向传播前都进行一次梯度清0,也就是调用
# 清除网络中所有参数的梯度
net.zero_grad()
loss function
neural network的损失函数可以参考这里,以MSE损失函数为例,过程只需要分两步,1. 定义损失函数, 2. 调用损失函数。例如
output = net(input)
target = torch.randn(10)
target = target.view(1, -1)
criterion = nn.MSELoss()
loss = criterion(output, target)
更新参数
更新参数的方法可以手动更新,也可以通过内置更新模块来更新
-
手动更新
以SGD为例,遍历网络中的每个参数,并更新,示例如下:
learning_rate = 0.01 for f in net.parameters(): f.data.sub_(f.grad.data * learning_rate) -
优化package
torch的优化package包含多种定义好的优化方法,使用方法也很简单,1. 定义优化方法,2. 调用优化方法
step()进行一次更新。例如optimizer = optim.SGD(net.parameters(), lr=0.01) optimizer.zero_grad() # 与nn.Module中的nn.Module.zero_grad() 一样 output = net(input) loss = criterion(output, target) loss.backward() optimizer.step()
一个典型的nn.Module神经网络的训练过程
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# ----------------- 定义网络 ----------------------
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# ---------------- 定义损失函数和优化器 ------------------
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# ---------------- 训练过程 ---------------------
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0): # traninloader 中包含了训练数据集,这里未展示
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
在GPU上训练
定义一个GPU设备,然后将网络和训练集和lable都放入该设备中
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device) # nn.Module.to
input, lables = data[0].to(device), data[1].to(device) # torch.Tensor.to
unsqueeze
unsqueeze()是指在扩展指定维度,例如
x = torch.tensor([1,2,3]) # shape为(3)
xx = x.unsqueeze(0) # 在第0个维度扩张,xx为 [[1,2,3]], shape 为(1,3)
xxx = x.unsqueeze(1) # 在第1个维度扩张,xxx 为[[1], [2], [3]], shape为(3, 1)